國產大模型,多模態能力都開始超越GPT-4-Turbo了??
權威榜單,中文多模態大模型測評基準SuperCLUE-V,新鮮出爐:
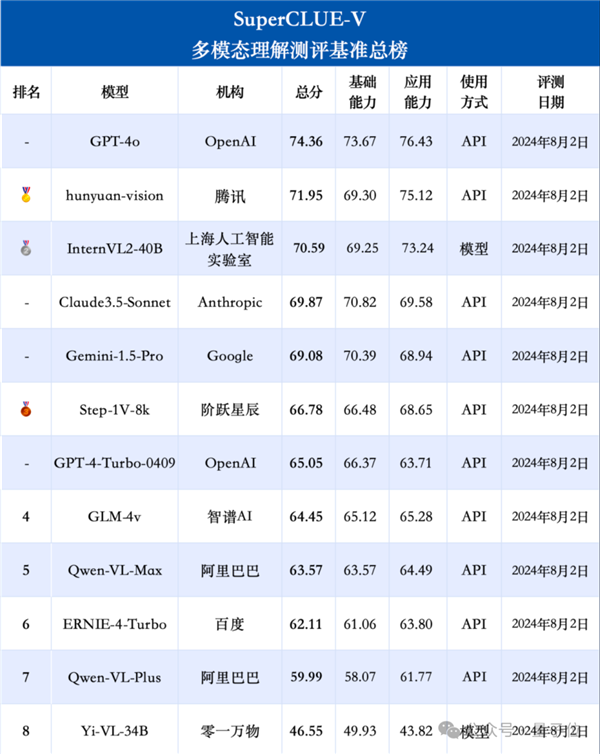
特別是騰訊的hunyuan-vision、上海AI Lab的InternVL2-40B,分別成為國內閉源和開源界兩大領跑者,甚至超過Claude-3.5-Sonnet和谷歌王牌Gemini-1.5-Pro。
雖然這次都還是被GPT-4o壓過,差距也確確實實縮小了很多。
(這個榜單旨在為中文領域提供一個多模態大模型多維度能力評估參考,GPT-4o等國外模型僅作對比參考,不參與排名哦)
hunyuan-vision也就是騰訊混元大模型的多模態版本了,除了開發者調用API之外,其實在騰訊元寶APP里免費就能體驗到。
一直以來,元寶主打“實用AI搭子”,似乎著重強調的是實用易用性;沒想到背著咱們偷偷拿模型去測評,還捧回來個國內第一,emmm……有點意思。
所以國產多模態大模型進化成什么樣了,光看分數還是不夠直觀,下面就拉出來溜溜。
多模態能力第一?這就上手玩
多模態測試,說實話有點不嘻嘻:還沒有出現“弱智吧”一樣公認效果拔群的“民間benchmark”。
但又嘻嘻:根本不耽誤我們碳基生物用千奇百怪的圖片來為難大模型。

那就開始吧!
Round 1.1:梗圖表情包理解
時間過得好快!昨兒已經立秋了。
夏天夏天悄悄過去,只留下可以用這張meme圖概括的心情:

問元寶,這張圖什么意思?得到的答案是:
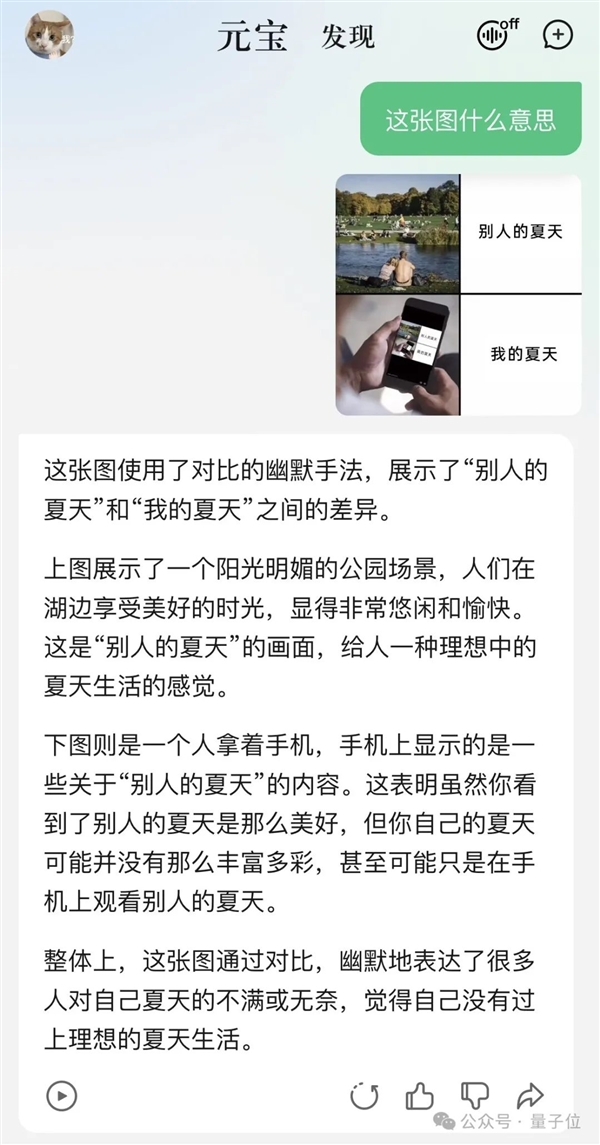
隨手測試的程序員祖傳題,元寶也輕松應對。

Round 1.2:照片內容識別
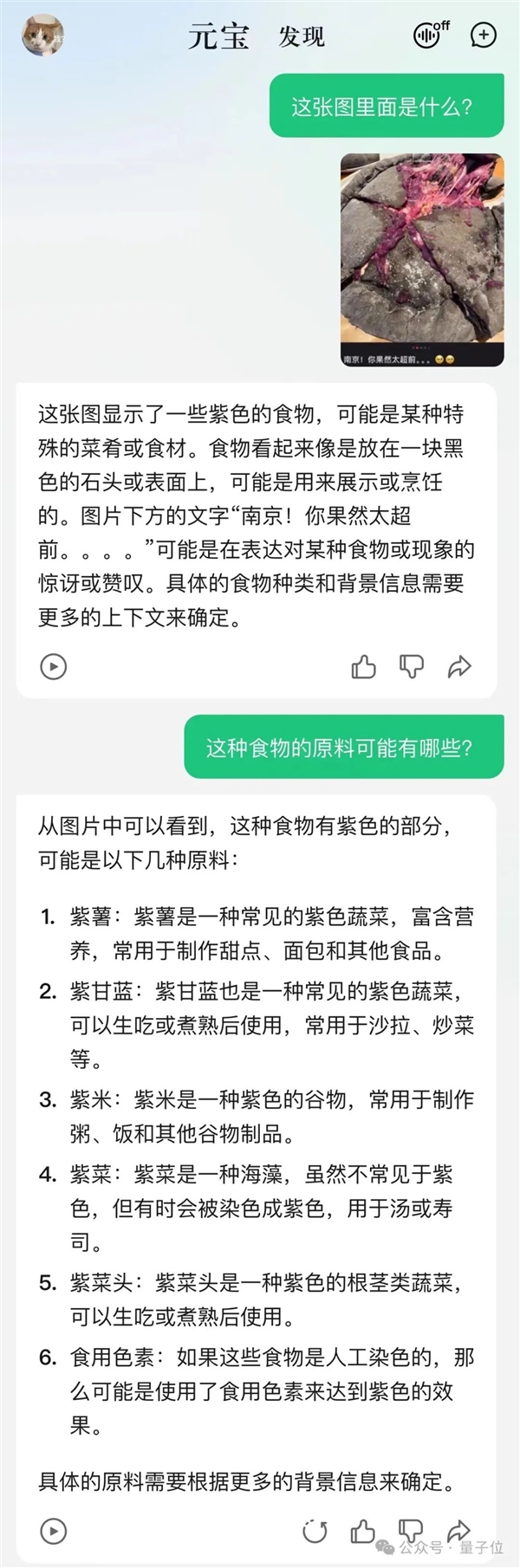
上來就是一道不走尋常路的“超前”題——編輯部好幾個人對著這張圖皺眉。
太黑暗了,不知是何物。

答案揭曉,這是近一個分享貼中,“南京本地人應該也受不了”的黑金榴蓮紫薯披薩。
元寶不僅能正確get到圖中“太超前”的含義,同時還根據圖片猜中了食物拿紫薯當原料。
至于沒有猜出榴蓮成分,也不能怪它,人類的黑暗料理不管是對AI還是對人類都真的太超前……
再來一道經典題目,數吉娃娃。
可以看到,混元元寶先是分析了題目中“吉娃娃”的外貌特征,然后分別告訴了九張圖中哪些是吉娃娃的照片。
不僅答得全對,還看出了圖中另一個物種是藍莓松餅。

Round 1.3:視覺錯覺挑戰
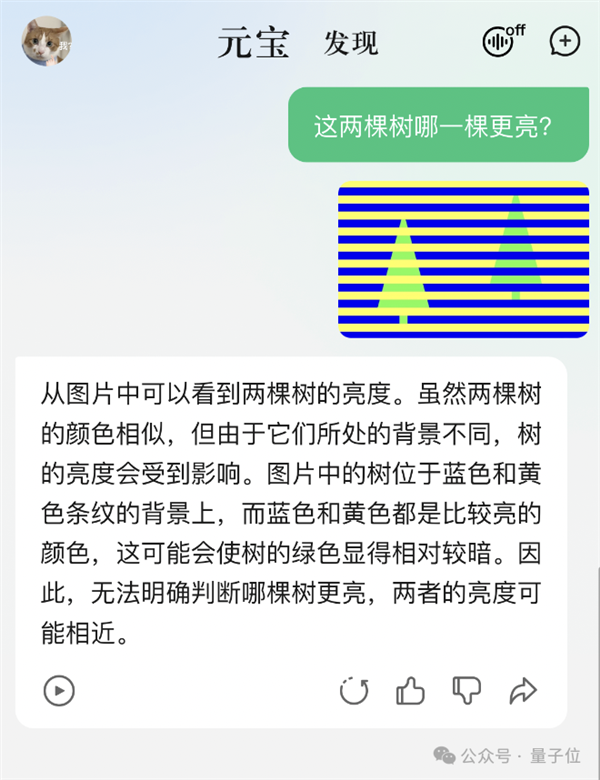
多模態大模型的視覺幻覺問題,是這兩年的熱門研究方向。
這些測試題真的很有迷惑性,別說大模型了,連人類也常常踩坑沒商量。
但騰訊元寶,就這么水靈靈地答對了!

當初難道一種大模型的“哪一棵樹更亮”,也謹慎地回答:
不過更難的錯覺挑戰它就不行了。讀圖片中隱藏信息的傻傻看不出,怎么問都說“沒有啊”:
不過講道理,這些題GPT-4V也答不上來,大約目前多模態大模型的階段性能力還沒邁過這道坎。
玩耍一番過后,接下來要動真格的!
測試元寶背后hunyuan-vision在實用場景下,表現如何。
Round 2.1:財報表現摘要讀取
每個季度、半年、年終的財報,打工人看了真的是腦闊痛。
這就把騰訊一季度財報表現摘要截圖扔給元寶,讓它幫忙淺做分析:
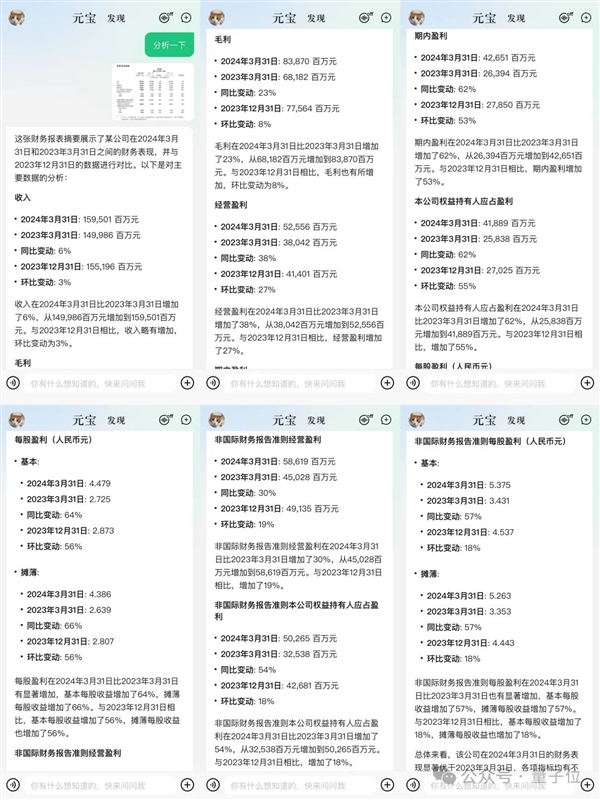
元寶讀取了圖標中的數據,還在后還小小總結了一把:
總體來看,該公司在2024年3月31日的財務表現顯著優于2023年3月31日,各項指標均有不同程度的增長,尤其是毛利、經營盈利和期內盈利的增長幅度較大。
Round 2.2:讀取(學術)圖表
先來一道沒那么學術的圖表識別題。
問,一張圖中的數字序列,缺少了哪一個?
元寶很好地讀圖,并正確填補了缺的那個數字:29。

然后隨機從一篇關于大模型數據的論文中,截圖喂過去。
它也能理解并給出詳細解釋,后還來幾句總結。
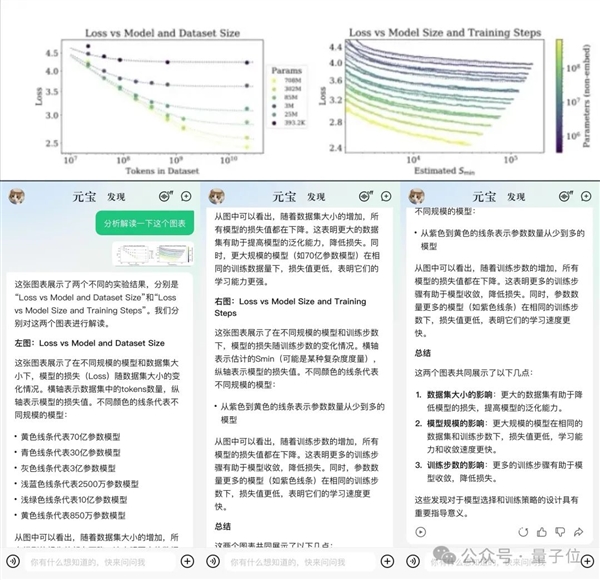
Round 2.3:行測找規律題
這一回合的后上大招——萬千人頭疼不已的行測找規律題。
題是下面這一道,prompt輸入:請從所給的四個選項中,選擇合適的一個填入問號處,使之呈現一定的規律性。
先提前透露正確答案,選C。
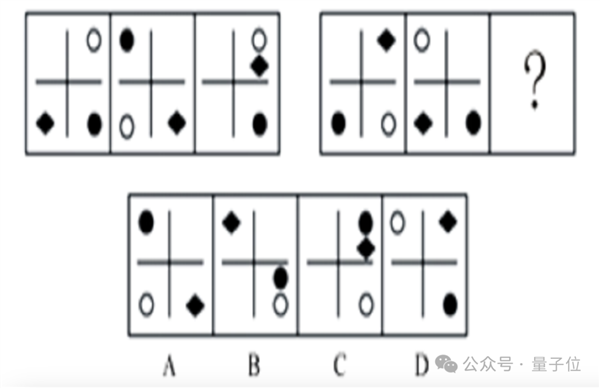
在公布自己的終答案之前,元寶嘰里呱啦進行了很長的過程分析(講真,看得人很緊張)。
后堅定地選了C選項,答對。

一道GPT-4V沒做對的附加題
先做個前情提要,此前研究人員們發現,GPT-4V更擅長解釋西方文化背景的圖像or帶有英文文字的圖像。
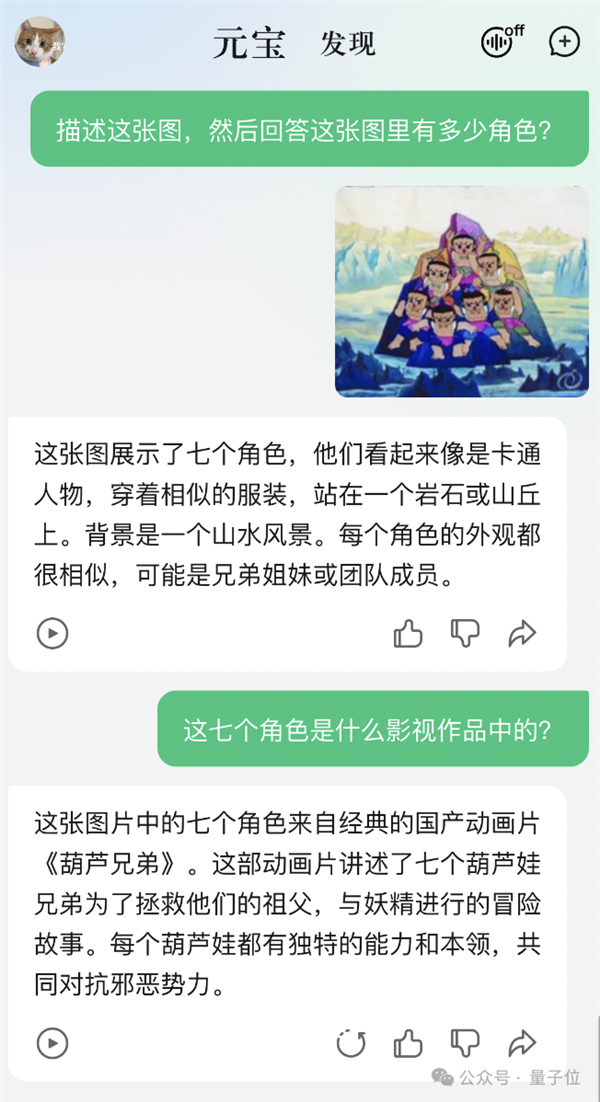
比如給AI看《白雪公主》,知道是有7個小矮人。換成《葫蘆娃》,7個就數成了10個,葫蘆山七彩峰也說成了冰山。

那么純國產大模型,總該表現好點了吧?直接原題譯中,丟過去。
好家伙,不僅數對了數量,還在追問中成功辨別這是《葫蘆兄弟》的截圖。
Nice!
騰訊元寶,真·AI實用搭子
看過這么多實測案例,是時候整體介紹一下背后的模型和整個APP了。
騰訊混元大模型,可以說是一位老朋友了。
去年9月首次對外亮相,之后一直保持著快速迭代。目前已擴展至萬億參數規模,由7萬億tokens的預訓練語料訓練而來,能力已覆蓋了文本、多模態理解及生成等。
在國內大模型中,騰訊混元率先完成MoE(Mix of Experts,專家混合)架構升級,也就是從單個稠密模型升級到多個專家組成的稀疏模型。
今年7月,還解鎖了一個單日調用tokens數達千億級的成就。

騰訊元寶,今年5月底剛剛上線,可能對很多人來說還是新朋友。
值得一提的是,在前一陣“9.11和9.9哪個大”的風波中,騰訊元寶表現不錯,無需額外提示自己就能答對。

騰訊元寶主打一個“實用AI搭子”,其中一個特色是APP、小程序和網頁都能訪問,聊天記錄多端同步。
比如在微信聊天中接收到的工作文檔,不用轉存到手機目錄,就可以直接到小程序選擇對話直接發給AI了,接下來是總結也好、生成也好都非常方便。
再拿多模態理解能力來說,無論是文檔截圖、人像風景、收銀小票,還是任意一張隨手拍的照片,元寶都能基于圖中內容給出自己的理解和分析。
背后的一個思考是不光要識別、理解,還要生成滿足用戶需求的內容。
從前面的測試中也可以看出,丟一個表情包給它,回答也會簡短,換成學術圖表,回答就會盡量詳盡、并且主動附加總結段落。
據騰訊介紹,混元大模型系列中的多模態理解模型,在視覺編碼、語言模型、訓練數據三方面做了深度的優化,能處理高達7k分辨率大16:1長寬比圖片,也是國內首個基于MoE的多模態大模型。
把Transformer開山之作,經典論文《Attention is all you need》拼成一個長圖,對騰訊元寶來說也完全不是難事,從引言到結論全文覆蓋。

而且騰訊元寶團隊這次特別透露,接下來會把更多精力放在融合模型多模態能力上。
反正騰訊嘛大家都熟悉,是國內大廠里重產品,重視打磨用戶體驗的。
比如近騰訊元寶開始往“深度”發展,先更新了“深度搜索”,又剛剛上線“深度長文閱讀”。
這些功能都是隱藏了技術細節、盡量減少對提示工程的需要,很多功能都是自動識別,一鍵觸發,不需要什么學習成本。
深度閱讀功能就初步整合了多模態理解能力,上傳一個論文PDF進去,生成的“精度”頁面中不僅有文字總結,還能把相應的圖表從文檔里拽出來。
在很多情況下,都不用來回翻原文對照了。

而且這一次,中文多模態大模型測評基準SuperCLUE-V榜單成績,也說明騰訊不只搞好了產品體驗,也非常看中背后模型基礎能力。
所以說,在多模態“圖生文”場景下,騰訊又能整出什么實用好活,就非常值得期待了。
本文鏈接:http://www.bbbearmall.com/news-131298.html強國產多模態剛剛易主!騰訊混元把GPT-4/Claude-3.5/Gemini-1.5都超了






















