OpenAI長期霸榜的SuperCLUE(中文大模型測評基準),終于被國產大模型反將一軍。
事情是這樣的。
自打SuperCLUE問世以來,成績第一的選手基本上要么是GPT-4,要么是GPT-4 Turbo,來感受一下這個feel:
(PS:共有6次成績,分別為2023年的9月-12月和2024年的2月、4月。)
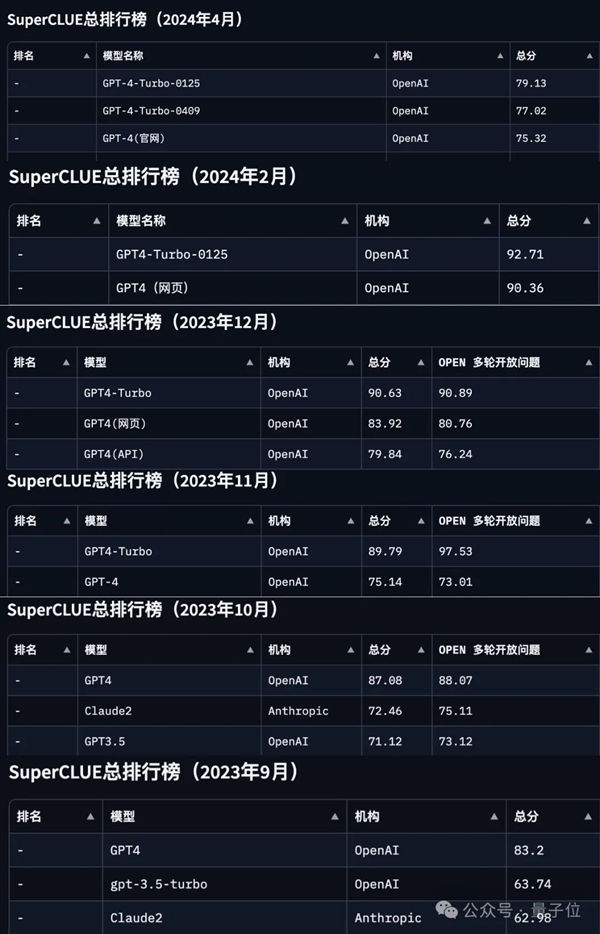
△圖源:SuperCLUE官方
但就在近,隨著一位國產選手申請的出戰,這一局面終是迎來了變數。
SuperCLUE團隊對其進行了一番全方位的綜合性測評,終官宣的成績是:
總分80.03分,超過GPT-4 Turbo的79.13分,成績第一!
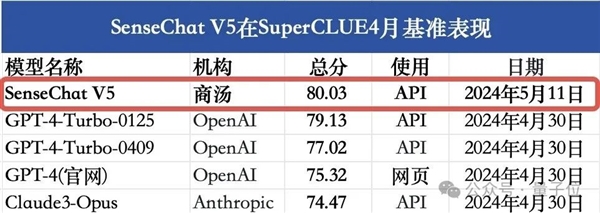
△圖源:SuperCLUE官方公眾號
而這位國產大模型選手,正是來自商湯科技的日日新5.0(SenseChat V5)。
并且SuperCLUE還給出了這樣的評價:
刷新了國內大模型好成績。
那么商湯在SuperCLUE的這個“首次”,又是如何解鎖的呢?
綜合、文科國內外第一,理科國內第一
首先我們來看下這次官方所搭建“擂臺”的競技環境。
出戰選手:SenseChat V5(于5月11日提供的內測API版本)
評測集:SuperCLUE綜合性測評基準4月評測集,2194道多輪簡答題,包括計算、邏輯推理、代碼、長文本在內的基礎十大任務。

△圖源:SuperCLUE官方報告
模型GenerationConfig配置:
temperature=0.01
repetition_penalty=1.0
top_p=0.8
max_new_tokens=2048
stream=false
至于具體的評測方法,SuperCLUE在已發布的相關報告中也有所披露:

△圖源:SuperCLUE官方報告
以上就是SuperCLUE公開的競技環境配置。
至于結果,除了剛才我們提到的綜合成績之外,官方還從文科和理科兩個維度,再做了細分的評測。
SenseChat V5在文科上的成績依然是打破了國內大模型的紀錄——
以82.20分的成績位居第一,同樣超越了GPT-4 Turbo。
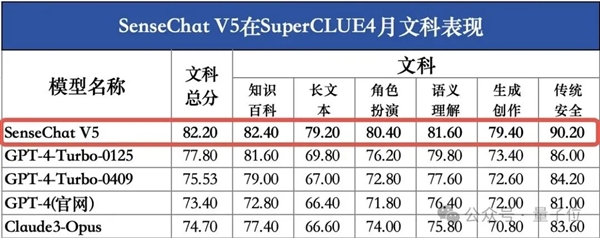
△圖源:SuperCLUE官方公眾號
在理科成績上,雖然SenseChat V5此次并沒有超越GPT-4-Turbo(低了4.35分),但整體來看,依舊在國內大模型選手中首屈一指,位列國內第一。
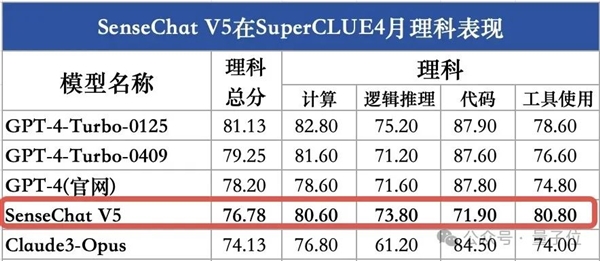
△圖源:SuperCLUE官方公眾號
除了文理科之外,SuperCLUE也還從國內和國外的整體平均水平上做了對比。
例如和國內大模型平均水平相比,其各項成績的“打開方式”是這樣的:
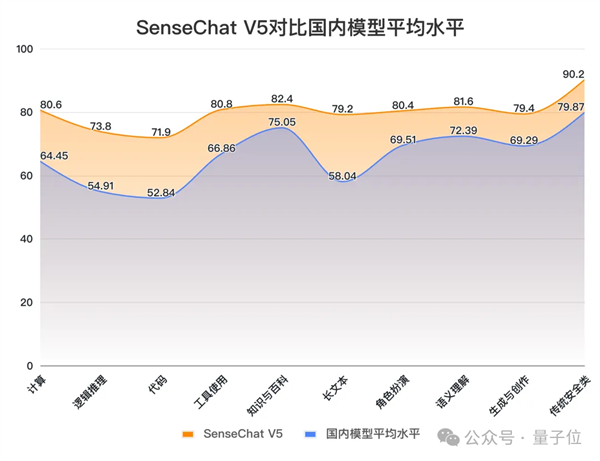
△圖源:SuperCLUE官方公眾號
而在與國外選手做性能對比時,我們可以明顯看到SenseChat V5文科能力優于國外選手,數理能力也非常優秀,代碼能力依然有提升空間。
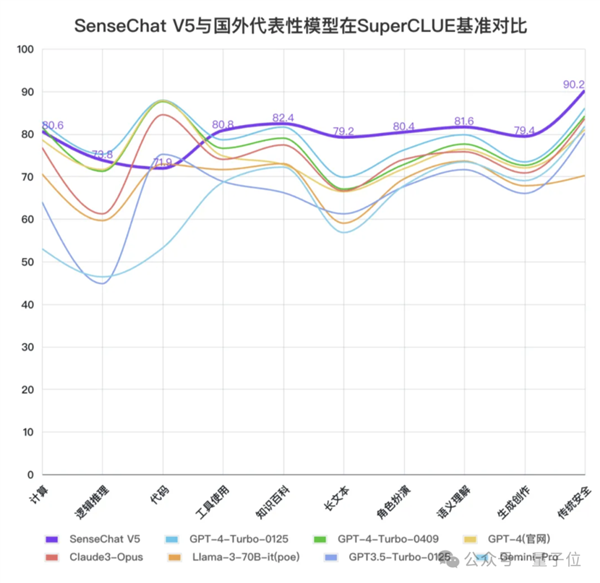
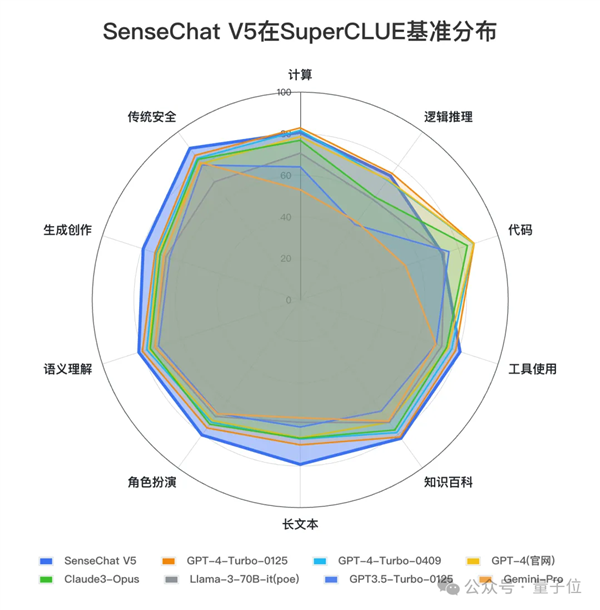
△圖源:SuperCLUE官方公眾號
不過有一說一,評測分數定然是代表大模型性能的一方面,但在應用為王的當下,更重要的一點或許就得看用的效果了。
實測SenseChat V5
SenseChat V5早在4月底便已經集成到了“商量”在線的對話應用中,因此我們現在就可以出題對它做一番考驗。
在邏輯測試方面,帶有文字陷阱的腦筋急轉彎,可以說是測試一個AI能力很好的例子,比如:
《紅樓夢》全書有百萬字,“紅樓夢”有幾個字?
若是仔細觀察這句話,不難發現其實句子前后并沒有太大的關聯,是一個比較典型的腦筋急轉彎。
對此,SenseChat V5給出的答案是:
《紅樓夢》作為中國古典文學的巔峰之作,其全文字數大約在70萬到80萬字之間,具體字數根據不同版本稍有差異。而標題“紅樓夢”這三個字,自然是只有三個字。這個標題凝練而富有深意,象征著作品的夢幻色彩和對封建家族興衰的深刻反思。
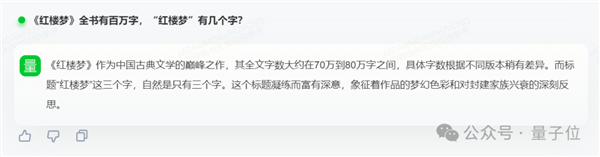
我們可以看到SenseChat V5不僅找出了問題的陷阱并做出了分析,給出的答案也是正確的。
對于數學的能力,我們設置了這樣的一個問題:
假設有一個池塘,里面有無窮多的水。現有2個空水壺,容積分別為5升和6升。如何只用這2個水壺從池塘里取得3升的水。

同樣的,SenseChat V5依舊是給出了每一個詳細的步驟和分析,并得到了終結果。
更直接的數學問題,例如找數字之間的規律,SenseChat V5也是信手拈來:

在中文理解方面,即使是給SenseChat V5一大段文言文,并且上難度連環發問,它是否可以hold得住?
請看結果:

后,有請“弱智吧Benchmark”:
網吧能上網,為什么弱智吧不能上弱智?

嗯,確實是有點實力在身上的。
如何做到的?
其實對于這個問題,商湯在4月底將自家日日新大模型SenseNova版本迭代到5.0之際,就已經有所透露;當時商湯鎖定的定位就是全面對標GPT-4 Turbo。
具體到技術,可以分為三大方面:
采用MoE架構
基于超過10TB tokens訓練,擁有大量合成數據
推理上下文窗口達到200K
首先,為了突破數據層面的瓶頸,商湯科技使用了超過10T的tokens,確保了高質量數據的完整性,使得大模型對客觀知識和世界有了基本的認知。
商湯還生成了數千億tokens的思維鏈數據,這是此次數據層面創新的關鍵,能夠激發大模型的強大推理能力。
其次,在算力層面,商湯科技通過聯合優化算法設計和算力設施來提升性能:算力設施的拓撲極限用于定義下一階段的算法,而算法的新進展又反過來指導算力設施的建設。
這也是商湯AI大裝置在算法和算力聯合迭代上的核心優勢。

在其它細節方面,例如訓練策略上的創新,商湯將訓練過程分為三個大階段(預訓練、監督微調、RLHF)和六個子階段,每個階段專注于提升模型的特定能力。
例如,單是在預訓練這個階段,又可以細分為三個子階段:初期聚焦于語言能力和基礎常識的積累,中期擴展知識基礎和長文表達能力,后期則通過超長文本和復雜思維數據進一步拔高模型能力。
因此在預訓練結束之際,整個模型就已經擁有了較高水平的基礎能力;但此時它的交互能力卻還沒有被激發出來,也就來到了第二階段的監督微調(SFT)和第三階段的人類反饋強化學習(RLHF)。
整體可以理解為先培養模型遵循指令和解決問題的能力,再調節其表達風格以更貼近人類的表達方式。接著,通過多維度的人類反饋強化學習過程,進一步改進模型的表達方式和安全性。
除此之外,商湯對于大模型的能力還有獨到的三層架構(KRE)的理解。
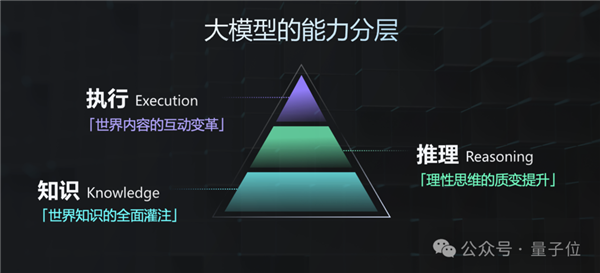
首先是在知識,是指世界知識的全面灌注。
目前大模型等新質生產力工具近乎都是基于此來解決問題,也就是根據前人已經解決過的問題的方案,來回答你的問題。
這可以認為是大模型能力的基本功,但更為高階的知識,應當是基于這樣能力下推理得到的新知識,這也就是這個架構的第二層——推理,即理性思維的質變提升。
這一層的能力是可以決定大模型是否夠聰明、是否可以舉一反三的關鍵和核心。
再在此之上,便是執行,是指世界內容的交互變革,也就是如何跟真實世界產生互動(就目前而言,具身智能在這一層是潛力股般的存在)。
三者雖相互獨立,但層與層之間也是緊密關聯,打一個較為形象的比喻就是“知識到推理是像大腦,推理到執行則像小腦”。
在商湯看來,這三層的架構是大模型應當具備的能力,而這也正是啟發商湯構建高質量數據的關鍵。
One More Thing
其實對于大模型測評這事,業界質疑的聲音也是層出不窮,認為是“刷分”、“刷榜”、“看效果才是重要的”。
對于這樣敏感的問題,商湯在與量子位的交流過程中也是直面并給出了他們的看法:
無論從用戶選擇合適模型的角度,還是從研究者進行操作研究的需要來看,對模型能力的評價是必不可少的。
這不僅幫助用戶和研究者了解不同模型的性能,也是推動模型發展的關鍵因素。
如果只針對一個公開的評測集進行優化(即刷分),是有可能提高模型在該評測集上的分數的。
評測不應只依賴單一數據集,而應通過多個評測集和第三方閉卷考試等方式相互印證,以此來得到更全面、更有說服力的模型性能評估。
以及對于國內近期各個大模型廠商正打得熱火朝天的價格戰,商湯將眼光放在了提供更深的端到端產品價值上,特別是在具備無限潛力且與生活應用更接近的移動端上,通過端云協同實現更優的計算成本但不損害模型的綜合能力。
這或許暗示了商湯將通過技術創新和優化成本結構,為未來可能入局的價格競爭做好了自己的規劃。
參考鏈接:
[1]https://www.superclueai.com/
[2]https://mp.weixin.qq.com/s/3pfOKtG6ar2h2fR6Isv_Xw
本文鏈接:http://www.bbbearmall.com/news-129578.htmlGPT-4 Turbo首次被擊敗!國產大模型拿下總分第一