12月5日消息,近日,騰訊混元大模型宣布文生視頻功能上線,一句話就能生成視頻。
此次開源的視頻生成大模型,參數量130億,是當前大的視頻開源模型。

用戶只需要輸入一段描述,即可生成視頻,目前的生成視頻支持中英文雙語輸入、多種視頻尺寸以及多種視頻清晰度。
目前該模型已上線騰訊元寶APP,用戶可在AI應用中的“AI視頻”板塊申請試用。
企業客戶通過騰訊云提供服務接入,目前API同步開放內測申請。
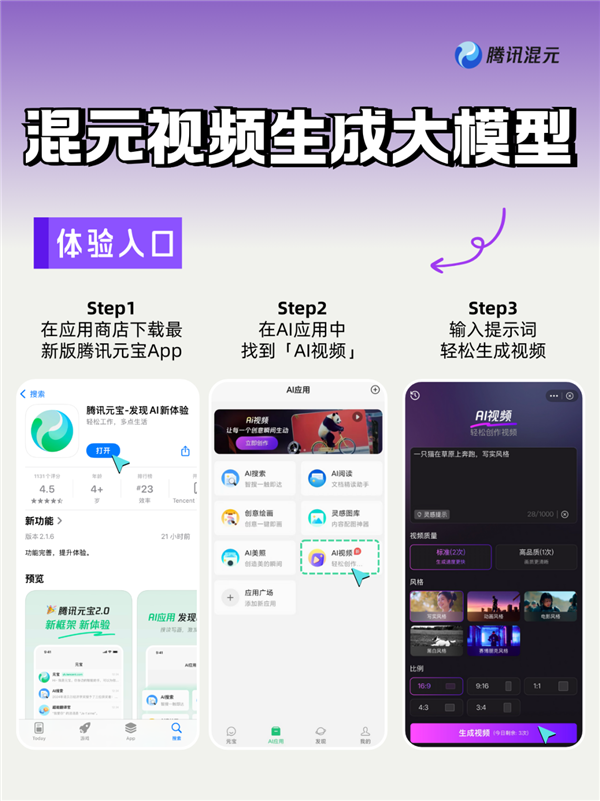
通過騰訊元寶APP-AI應用-AI視頻即可使用該功能(前期需申請)
在與國內外多個頂尖模型的評測對比顯示,混元視頻生成模型在文本視頻一致性、運動質量和畫面質量多個維度效果領先,在人物、人造場所等場景下表現尤為出色。
騰訊混元生成視頻大模型可以實現超寫實畫質、生成高度符合提示詞的視頻畫面,畫面流暢不易變形。

比如,在沖浪、跳舞等大幅度運動畫面的生成中,騰訊混元可以生成非常流暢、合理的運動鏡頭,物體不易出現變形;光影反射基本符合物理規律,在鏡面或者照鏡子場景中,可以做到鏡面內外動作一致。
同時,模型還可以實現在畫面主角保持不變的情況下自動切鏡頭,這是業界大部分模型所不具備的能力。

本文鏈接:http://www.bbbearmall.com/news-132875.html一句話生成視頻!騰訊混元視頻生成能力對外開放:使用教程來了